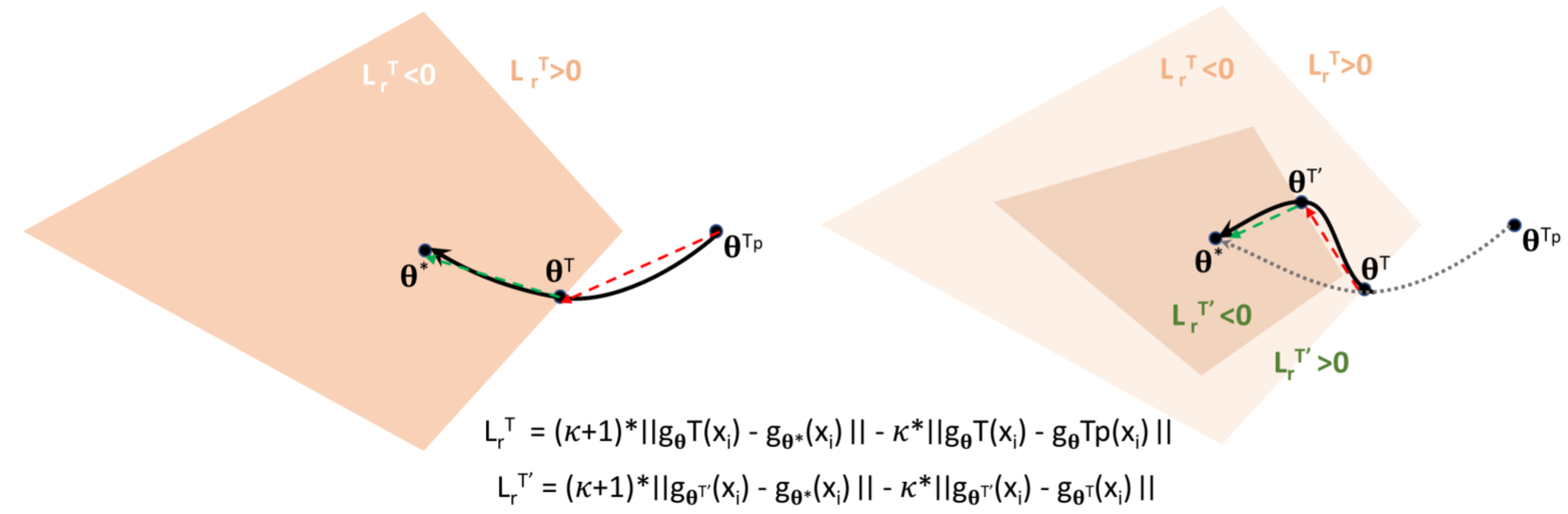
Deep neural networks (DNNs) are powerful learning machines that have enabled breakthroughs in several domains. In this work, we introduce a new retrospective loss to improve the training of deep neural network models by utilizing the prior experience available in past model states during training. Minimizing the retrospective loss, along with the task-specific loss, pushes the parameter state at the current training step towards the optimal parameter state while pulling it away from the parameter state at a previous training step. Although a simple idea, we analyze the method as well as to conduct comprehensive sets of experiments across domains - images, speech, text, and graphs - to show that the proposed loss results in improved performance across input domains, tasks, and architectures.
This study was funded by ...
If you have any questions about this work, please contact us at cs17btech11038@iith.ac.in